
-
 极资源官方
极资源官方
- 热度7505℃
1. 数据发送过程
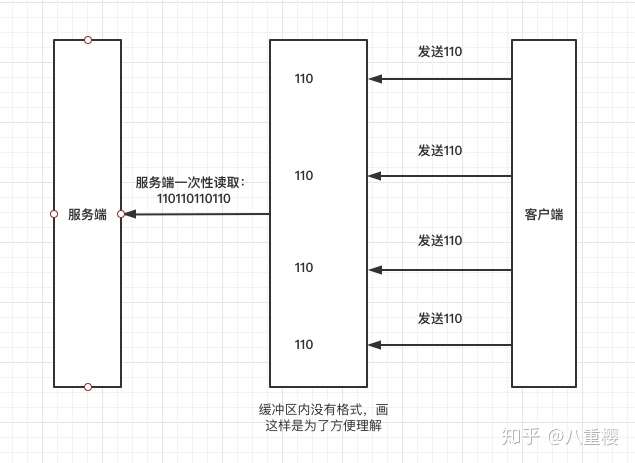
首先由客户端将数据发往缓冲区 (服务端并不是直接收到的), 对于客户端来说,这次的数据即是发送成功了, 对于服务端是否真正的收到他是不知道的, 然后再由服务端从缓冲区中读取数据。图解:

2. 什么是数据边界
因为 TCP 是流式传输,对于服务端来说并不知道此时在缓冲区内的数据是一次请求还是两次请求的,所以在服务端接收数据时需要根据指定字符或约定长度来对数据进行分包,这个分包的标志即是数据边界。否则可能会出现一次读取两条或多条数据,造成读取、解析数据出错。
2.1 代码演示
可以用代码实现一下,假设客户端死循环往缓冲区不停输入 “1”,即相当于每次的报文内容都是 1, 那么在服务端读取时收到的数据就是随机长度的。
客户端代码
$client = new Swoole\Client(SWOOLE_SOCK_TCP);
if ($client->connect('127.0.0.1', 9501, -1)) {
while(true) {
$client->send(1);
}
}
$client->close();
服务端代码
$server = new Swoole\Server('127.0.0.1', 9501);
$server->on('connect', function($server, $fd){
echo "client : ".$fd." connect";
});
$server->on('receive', function($server, $fd, $from_id, $data){
echo "receive:". $data.PHP_EOL;
});
$server->on('close', function($server){
});
运行结果
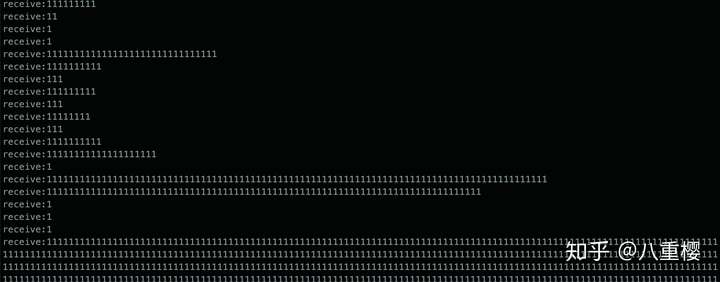
可以看到运行结果,服务端获取到的数据完全是随机的,有长有短,那么接下来我们说下如何解决这个问题。
3.EOF 解决方案
第一种解决方案类似于我们 http 请求头的分隔符,在每次发送的数据包结尾处使用 \r\n (可以配置) 来结尾, 当服务端从缓冲区中读取数据, 根据指定字符来分割数据包,EOF 有两种配置方案:
3.1 open_eof_check
首先放出配置方式:
$server->set([
'open_eof_check' => true,
'package_eof' => "\r\n"
]);这种配置方式会对客户端发来的数据包进行检测, 当发现结尾是 \r\n 时,才会投递给 worker 进程, 也就是我们的 onReceive 回调,否则会一直拼接数据包,直到超出缓冲区或者超时才终止。 但此方法有一个问题是可能会一次性收到多个数据包,因为他是从数据包的结尾处来进行检查的,在数据内容中存在 \r\n 时程序并不会发现,需要我们自己在应用代码中再次使用 \r\n 来拆分数据包。
客户端运行代码
$client = new Swoole\Client(SWOOLE_SOCK_TCP);
if ($client->connect('127.0.0.1', 9501, -1)) {
while(true) {
$send2 = "Hello World \r\n";
$client->send($send2);
}
}
$client->close();
服务端代码
$server = new Swoole\Server('127.0.0.1', 9501);
$server->set([
'open_eof_check' => true,
'package_eof' => "\r\n"
]);
$server->on('connect', function($server, $fd){
echo "client : ".$fd." connect";
});
$server->on('receive', function($server, $fd, $from_id, $data){
echo "receive:". $data;
});
$server->on('close', function($server){
});
$server->start();
运行结果
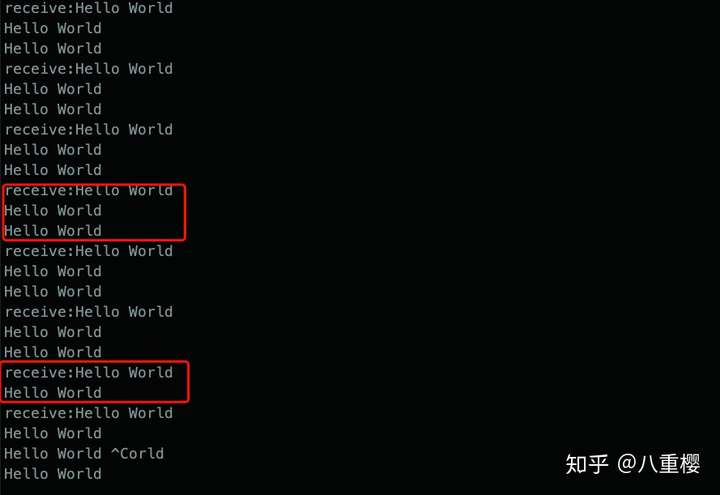
3.2 open_eof_split
配置方式:
$server->set([
'open_eof_split' => true,
'package_eof' => "\r\n"
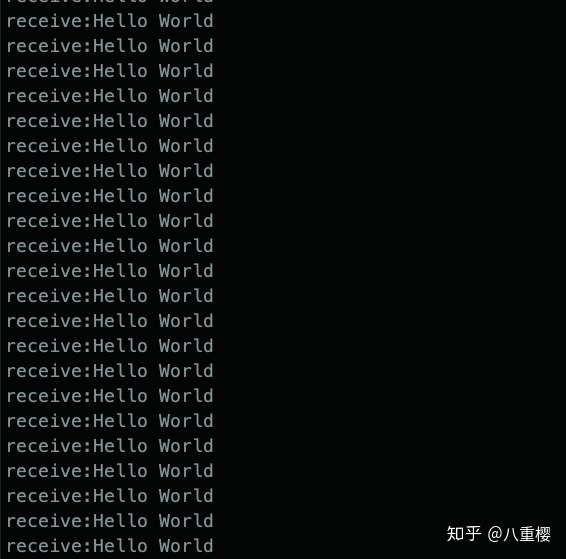
]);这种配置方式,服务端会对客户端发来的数据逐个字符进行检查,遇到 \r\n 就发送给 worker 进程,可以有效实现分包,但缺点是性能比较差。
运行结果:可以看到每次接收到一个 Hello World(代码我就不贴了, 只把服务端 set 配置改一下, 其他都一样)
3.3 open_eof_check 和 open_eof_split 差异
- open_eof_check 只检查接收数据的末尾是否为 EOF,因此它的性能最好,几乎没有消耗
- open_eof_check 无法解决多个数据包合并的问题,比如同时发送两条带有 EOF 的数据,底层可能会一次全部返回
- open_eof_split 会从左到右对数据进行逐字节对比,查找数据中的 EOF 进行分包,性能较差。但是每次只会返回一个数据包
4. 固定包头 + 包体解决方案
引用一段官方文档的描述:
包长检测提供了固定包头 + 包体这种格式协议的解析。启用后,可以保证 Worker 进程 onReceive 每次都会收到一个完整的数据包。
长度检测协议,只需要计算一次长度,数据处理仅进行指针偏移,性能非常高,推荐使用。
可见官方是推荐使用这种方式的,就是配置比其他方案要复杂一些, 首先贴一下配置:
$server->set([
// 打开包长检测特性
'package_length_check' => true,
// 包头中某个字段作为包长度的值,底层支持了 10 种长度类型。可参考 pack() 方法
'package_length_type' => 'N',
// length 长度值在包头的第几个字节。
'package_length_offset' => 8,
// 从第几个字节开始计算长度,一般有 2 种情况:
//length 的值包含了整个包(包头 + 包体),package_body_offset 为 0
//包头长度为 N 字节,length 的值不包含包头,仅包含包体,package_body_offset 设置为 N
'package_body_offset' => 16,
// 设置最大数据包尺寸,单位为字节
'package_max_length' => 81920
]);
下面是一个数据包结构例子,可以很好的体现了字段含义。
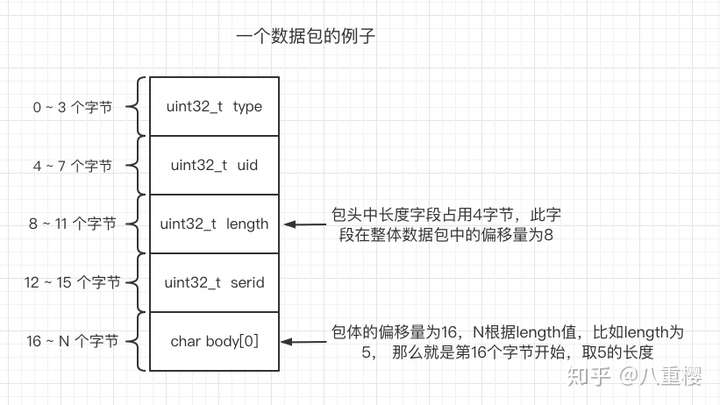
以上通信协议的设计中,包头长度为 4 个整型,16 字节,length 长度值在第 3 个整型处。因此 package_length_offset 设置为 8,0-3 字节为 type,4-7 字节为 uid,8-11 字节为 length,12-15 字节为 serid。
下面来说一下代码实现:
客户端代码:
$client = new Swoole\Client(SWOOLE_SOCK_TCP);
$data = "123456789012345678901234567890";
$type = 0x30;
$uid = 0x123;
$length = strlen($data);
$serid = 0x15;
$head = pack("N4", $type, $uid, $length, $serid);
$body = pack("a{$length}", $data);
$message = $head.$body;
if ($client->connect('127.0.0.1', 9502, -1)) {
$client->send($message);
echo $client->recv();
}
$client->close();
服务端代码:
$serv = new Swoole\Server('127.0.0.1', 9502);
$serv->set([
'open_length_check' => true,
'package_max_length' => 81920,
'package_length_type' => 'N',
'package_length_offset' => 8,
'package_body_offset' => 16,
]);
$serv->on('connect', function($server, $fd){
echo $fd. " Connect !".PHP_EOL;
});
$serv->on('receive', function($server, $fd, $from_id, $data){
var_dump($data); // 源数据
$tmp = unpack("Ntype/Nuid/Nlength", $data);
$unpacking = unpack("Ntype/Nuid/Nlength/Nserid/a{$tmp['length']}body", $data);
var_dump($unpacking); // 解包后数据
$server->send($fd, " Server Receive Data: ". $unpacking['body']);
});
$serv->on('close', function($server){
});
$serv->start();
客户端运行结果

服务端运行结果
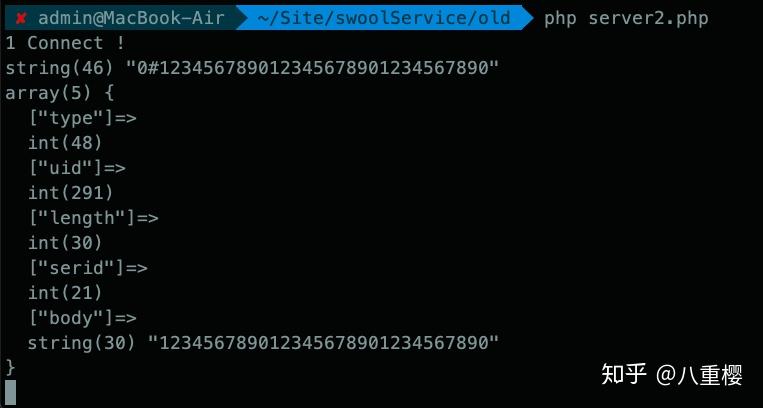
可以看到 客户端成功的把发送的数据回显, 服务端也打印出了接收到的所有数据, 其中有些字段在发送时是 16 进制的, 所以服务端在接收到之后需要进行进制转换, 我这里没有进行转换, 所以显示的数据是 10 进制的。
5. 总结
通过对比可以看出使用固定包头 + 包体的方式是效率最高的一种, 因为他是按照固定长度去读取的。期间专门去了解了 pack 函数的使用方法,但也不确定这么写到底对不对,如果有其他了解的仁兄可以慷慨解答一下,网上相关资料有点少,官方文档上也只给出了几个字段的释义。
6. 扩展知识:
6.1 字节序
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
举例来说,数值 0x2211 使用两个字节储存:高位字节是 0x22,低位字节是 0x11。
- 大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
- 小端字节序:低位字节在前,高位字节在后,即以 0x1122 形式储存。
这个前和后指的是内存地址,计算机处理字节时是不知道高低字节之分的,它只知道按顺序读取字节,先读第一个字节,再读第二个字节。
例如: 0x1234567 的读取顺序:
:

友情提示:垃圾评论一律封号...