
-
 极资源官方
极资源官方
- 热度7509℃
什么是Bellman-Ford算法?Bellman-Ford算法是一种堪称完美的解决一个点到其他各点的最短路径的算法。Bellman-Ford算法的核心代码只有4行,可以解决负权边的问题。
Bellman-Ford算法的核心代码只有四行,如下
for(k=1; k<=n-1; k++)
for(i=1; i<=m; i++)
if(dis[v[i]] > dis[u[i]] + w[i])
dis[v[i]] = dis[u[i]] + w[i];Bellman-Ford算法的核心代码意思是:遍历每一个点,其中每一次遍历时,遍历所有的边,对每个边进行一次松弛操作。
松弛什么?请点击查看。算法十一:Dijkstra算法 - 一个点到各个点的最短路径
现在有如下图,共5个点5条边,边都是有向边,其中点1到点2的距离为负数。如下:
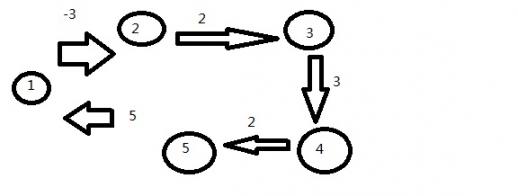
为什么会进行n-1次的循环呢?因为在不包含负权回路的路径中,n个点最多有n-1条边。在负权边中,负权回路会使最短路径不断的变小,永无止境。
完整代码如下:
#include <stdio.h>
int main(){
int dis[10], i, k, m, n, u[10], v[10], w[10];
int maxValue = 9999;
//源点为1
int start = 1;
//读入点的个数n,边的个数m
scanf("%d %d", &n, &m);
//读入边
for(i=1; i<=m; i++){
scanf("%d %d %d", &u[i], &v[i], &w[i]);
}
//初始化dis数组。dis数组表示源点到各个点的初始距离,初始化时都为无穷大
for(i=0; i<=n; i++){
dis[i] = maxValue;
}
//源点到源点的距离为0
dis[start] = 0;
//Bellman-Ford算法的核心语句
for(k=1; k<=n-1; k++){
for(i=1; i<=m; i++){
if(dis[v[i]] > dis[u[i]] + w[i]){
dis[v[i]] = dis[u[i]] + w[i];
}
}
}
for(i=1; i<=n; i++){
printf("%d ", dis[i]);
}
return 0;
}输入
5 5 2 3 2 1 2 -3 1 5 5 4 5 2 3 4 3输出
0 -3 -1 2 4
Bellman-Ford算法的时间复杂对为O(MN)。
我们可以更加完善上面的代码。比如我们已经知道了使用Bellman-Ford算法不能包含负权回路,那么我们需要检测图中是否包含负权回路:
sign = 0
for(i=1; i<=m; i++)
if(dis[v[i]] > dis[u[i]] + w[i])
flag = 1;
if(sign == 1)
printf("此图有负权回路"); 另外,在n-1轮循环中,若n-3轮已经松弛完毕,那么n-2和n-1两次循环便毫无意义,因此增加判断,若第x轮dis数组已经不再发生变化了,则不在继续进行循环。
新版的完整代码如下:
#include <stdio.h>
int main(){
int dis[10], i, k, m, n, u[10], v[10], w[10], sign, check;
int maxValue = 9999;
//源点为1
int start = 1;
//读入点的个数n,边的个数m
scanf("%d %d", &n, &m);
//读入边
for(i=1; i<=m; i++){
scanf("%d %d %d", &u[i], &v[i], &w[i]);
}
//初始化dis数组。dis数组表示源点到各个点的初始距离,初始化时都为无穷大
for(i=0; i<=n; i++){
dis[i] = maxValue;
}
//源点到源点的距离为0
dis[start] = 0;
//Bellman-Ford算法的核心语句
for(k=1; k<=n-1; k++){
//本轮dis数组是否发生变化
ckeck = 0;
for(i=1; i<=m; i++){
if(dis[v[i]] > dis[u[i]] + w[i]){
dis[v[i]] = dis[u[i]] + w[i];
check = 1;
}
}
//本轮没有发生松弛,则不再继续进行了。
if(ckeck == 0){
break;
}
}
sign = 0
for(i=1; i<=m; i++)
if(dis[v[i]] > dis[u[i]] + w[i])
sign = 1;
if(sign == 1){
printf("此图有负权回路");
}else{
for(i=1; i<=n; i++){
printf("%d ", dis[i]);
}
}
return 0;
} 在第每一轮循环中,其实只对上一次发生了松弛的边的相邻边判断是否需要松弛,因此,没有必要每次都进行m次循环(遍历所有的边判断是否需要松弛)。比如第一轮松弛了1->2和1->5,那么第二次仅仅判断2->3和5->4这两个边是否需要松弛,而不需要遍历所有的边。
在这种情况下,我们引入队列,将需要松弛的点加入队列。每个点仅仅需要入队一次即可,因为入队多次是没有意义的。初始时我们将1号点(源点)加入队列。然后开始遍历队列,对队列中每个点的边进行松弛。队列为空时所得结果便是一个点到其他所有点的最短路径。这是对上述的Bellman-Ford算法一种极大的优化。当然,在最坏的情况下,和Bellman-Ford算法的时间复杂度是一样的,即O(MN)。此优化也可以解决负权边。
完整代码如下:
#include <stdio.h>
int main(){
int dis[10] = {0}, i, j, k, m, n, u[10], v[10], w[10];
int book[10] = {0};
//first数组和next数组用来建立领接表,即first记录一个边的开头,比如第2号边的开头是点a,那么first[a]=2,a开头的下一个边是第5号边,则next[5]=a,组成一个链表的形式
int first[10], next[10];
int queue[100] = {0}, head = 1, tail = 1;
int maxValue = 9999;
//源点为1
int start = 1;
//读入点的个数n,边的个数m
scanf("%d %d", &n, &m);
//初始化dis数组。dis数组表示源点到各个点的初始距离,初始化时都为无穷大
//book用来标记那个点已经入队了,因为队列中同时出现同一个点多次是没有意义。
//first用来标记第i条边的起点
for(i=0; i<=n; i++){
dis[i] = maxValue;
book[i] = 0;
first[i] = -1;
}
//源点到源点的距离为0
dis[start] = 0;
//读入边
for(i=1; i<=m; i++){
scanf("%d %d %d", &u[i], &v[i], &w[i]);
//使用first和next两个数组建立领接表
next[i] = first[u[i]];
first[u[i]] = i;
}
//源点入队
queue[tail] = start;
tail++;
//标记已经入队的点
book[i] = start;
while(head < tail){
//当前需要处理的点,是队首的点,处理队首开头的所有边
k = first[queue[head]];
//扫描这个点开头的所有边
while( k != -1){
if(dis[v[k]] > dis[u[k]] + w[k]){
dis[v[k]] = dis[u[k]] + w[k];
if(book[v[k]] == 0){
queue[tail] = v[k];
tail++;
book[v[k]] = 1;
}
}
k = next[k];
}
//这个点开头的所有边都处理完了,就出队
book[queue[head]] = 0;
head++;
}
for(i=1; i<=n; i++){
printf("%d ", dis[i]);
}
getchar();getchar();
return 0;
}输入5 5 2 3 2 1 2 -3 1 5 5 4 5 2 3 4 3
输出
0 -3 -1 2 4Ps:本算法参考《啊哈!算法》一书。
友情提示:垃圾评论一律封号...